GMM : Gaussian Mixture Models¶
目次
sklearn.mixture はガウス混合分布モデルの学習, サンプリング, 評価をデータから可能にするパッケージです. コンポーネントの適切な数の探索を手助けする機能も提供しています.
ガウス混合モデルは, すべてのデータポイントが有限数の未知のパタメータを持つガウス分布の混同から生み出されたものだと過程する確率モデルです. 混合モデルを K-means クラスタリングをデータの共分散構造だけでなく, 潜在ガウス分布の中心についての情報を組み込み一般化したものであると考えることが可能です.
使用例¶
とりあえず GMM の学習を行う例を以下に示します. ここではデータセット iris の2次元分のデータを教師なしで学習し, 混合正規分布の密度を計算し,可視化するスクリプトを作成しています.
出力¶
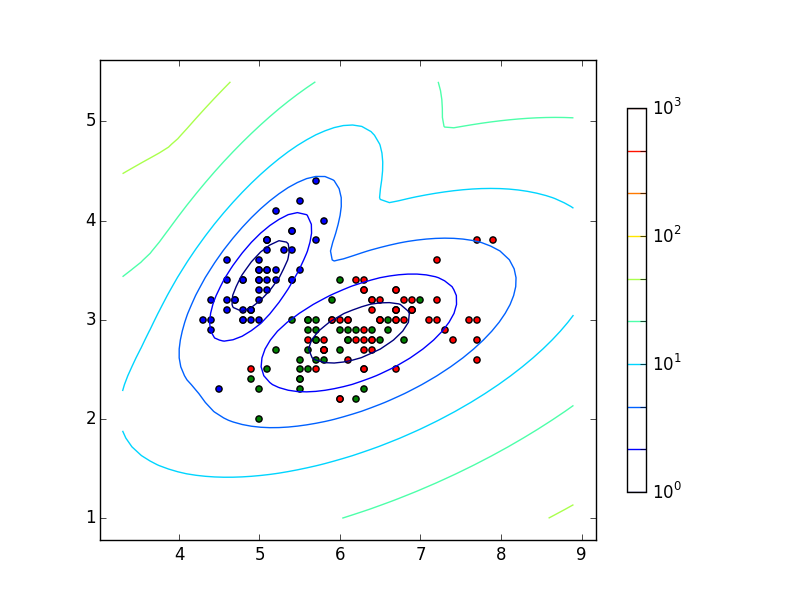
以下に図の見方を解説します. まず,X軸,Y軸ですが,これは学習データの一次元目,二次元目を表しています.
図中にある散布図は学習データそのものです. 三種類の色がありますが,これらは菖蒲の種類ごとに色分けをしています.
- 使用したサンプルデータの詳細は iris とは を確認してください.
GMM による学習結果は図中の等高線で表現されています. これは学習された混合正規分布の高さであると理解していただければよいかと思います. 曲線の色はそれぞれの等高線ごとに分けています.
ある高さ以上の部分で曲線が2つに分かれます. これはある閾値を設定すれば, iris のデータを2つに分けることができるということを 示しています(正確な言い方をすれば,今回与えた iris のデータは2つの正規分布の混同 であるということです).
GMM はこのように,データを複数の正規分布の混合であると考え, 具体的にはどのようなパラメータの正規分布であるのかを推定するモデルです.
コードの解説¶
基本的にはスクリプトを読んでいただければ, 何をやっているのかは分かるかと思います(そういう方はこの部分は読み飛ばしてくださ いな).
ここでは,スクリプティングに慣れていない方のために,軽く解説を行います.
ライブラリの読み込み¶
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
from sklearn import datasets
from sklearn import mixture
GMM に必要なライブラリは最後の部分のみです.
その他のライブラリは以下の目的で読み込んでいます.
- import numpy as np : 学習結果から正規分布の密度を計算する範囲を決定
- import matplotlib.pyplot as plt : 可視化
- from matplotlib.colors import LogNorm : 目盛りの作成
- from sklearn import datasets : 学習データ iris の読み込み
データの読み込み¶
やっている作業は以下の通りです.
- datasets.load_iris() : iris の読み込み
- iris.data[:, :2] : 学習するデータの指定
- iris.target : 正解ラベルの取得
- 今回は出力をイメージしやすい二次元で表現するため,学習データも二次元にしています.
- 使用したサンプルデータの詳細は iris とは を確認してください.
学習¶
mixture.GMM(n_components=2, covariance_type='full')
clf.fit(datas)
一行目では GMM のパラメータを指定しています.
GMM オブジェクトに関する詳しい説明は GMM オブジェクトについて を参照ください.
n_components : クラスタ数(デフォルトでは1)
- covariance_type : 共分散の種類を指定
- ‘spherica’, ‘tied’, ‘diag’, ‘full’ のいずれかを指定します(デフォルトでは diag).
- このパラメータに関しては GMM オブジェクトの共分散パラメータについて で説明します.
二行目は実際にデータを与え,学習を行っています.
可視化¶
可視化部分に関しては matplotlib を使用しました. そのため,ここでの解説は省略します.
GMM オブジェクトについて¶
パラメータ¶
- n_components : int, optional
- Number of mixture components. Defaults to 1.
- covariance_type : string, optional
- String describing the type of covariance parameters to use.
- Must be one of spherical, tied, diag, full.
- Defaults to diag.
- random_state: RandomState or an int seed (0 by default)
- A random number generator instance
- min_covar : float, optional
- Floor on the diagonal of the covariance matrix to prevent overfitting.
- Defaults to 1e-3.
- thresh : float, optiona
- Convergence threshold.
- n_iter : int, optional
- Number of EM iterations to perform.
- n_init : int, optional
- Number of initializations to perform.
- the best results is kept
- params : string, optional
- Controls which parameters are updated in the training process.
- Can contain any combination of ‘w’ for weights, ‘m’ for means, and ‘c’ for covars.
- Defaults to ‘wmc’ .
- init_params : string, optional
- Controls which parameters are updated in the initialization process.
- Can contain any combination of ‘w’ for weights, ‘m’ for means, and ‘c’ for covars.
- Defaults to ‘wmc.
返り値¶
- weights_ : それぞれのコンポーネントの混合比
- means_ : それぞれのコンポーネントの平均
- covars_ : それぞれのコンポーネントの共分散
- converged_ : fit() が収束したか否か
メゾッド¶
- aic(X) : 現在当てはめているモデルの 赤池情報量基準 (AIC) を算出
- bic(X) : 現在当てはめているモデルの ベイズ情報量基準 (BIC) を算出
- eval(args, kwargs) : 非推奨. GMM.eval は 0.14 から GMM.score_samples に変更され 0.16 で削除される.
- fit(X) : モデルのパラメータを EM アルゴリズムで推定
- get_params([deep]) : Get parameters for this estimator.
- predict(X) : データに対するラベルの予測
- predict_proba(X) : Predict posterior probability of data under each Gaussian in the model.
- sample([n_samples, random_state]) : Generate random samples from the model.
- score(X) : Compute the log probability under the model.
- score_samples(X) : Return the per-sample likelihood of the data under the model.
- set_params(params) : Set the parameters of this estimator.