Scikit-learn : 機械学習ライブラリ¶
このページについて¶
このページでは python の機械学習用ライブラリ Scikit-learn についてのメモをします. 導入方法,基本的な使い方,サンプルデータに関してはこのページに記述し, 各種,機械学習の方法に関する説明は Contents 以下のページに記述します.
これは何??¶
Scikit-learn は python で 機械学習関係, つまり, 分類, 回帰, クラスタリング を行うためのライブラリです. numpy, scipy などを使いやすくまとめたものという認識でもよいでしょう. モデルの評価, クロスバリデーション, パラメータのグリッドサーチなどもあります.
Install¶
例の如く, pip を使用します.
$ sudo pip install scikit-learn
警告
pip を使用した導入に関して
Linux を使用している場合のみかもしれませんが, numpy, scipy を事前に導入して おかないとコケる場合があるようです.
基本的な使い方¶
Scikit-learn を使用する場合基本的には以下の手順でスクリプトを記述します.
- 学習データを読み込む
- テストデータと訓練データに分ける
- 使用する分類器を宣言し,パラメータを渡す
- 訓練データで学習を行う
- テストデータの予測を行う
たとえば線形カーネルの SVM を使用し学習を行う例を以下に示します.
>>> # -*- coding: utf-8 -*-
>>> from sklearn.datasets import load_digits
>>> from sklearn.cross_validation import train_test_split
>>> from sklearn.svm import LinearSVC
>>> digits = load_digits(2) # データの読み込み
>>> # 訓練データとテストデータに分割
>>> data_train, data_test, label_train, label_test = train_test_split(digits.data, digits.target)
>>> estimator = LinearSVC(C=1.0) # 分類器の指定とパラメータの指定
>>> estimator.fit(data_train, label_train) # 訓練データで学習
>>> label_predict = estimator.predict(data_test) # テストデータの予測
上記の例において本質的な部分は下 3 行です. まず分類器の指定は以下のように行います.:
estimator = LinearSVC(C=1.0)
LinearSVC の部分が線形カーネルの SVM を使用して学習を行いますという宣言です. 要は Scikit-learn で実装されている分類器のインスタンスを作成します.
訓練データを学習させるためには上記のインスタンスから fit を呼びだせばよいわけです:
estimator.fit(data_train, label_train)
これで estimator の中には訓練データから学習されたモデルが入ります.
最後に学習されたモデルを未知のデータに当てはめます. 今回の例の場合,estimator の predict を呼びだせばよいです. これが最後の行です.:
label_predict = estimator.predict(data_test)
これで label_predict の中に分類結果が入ります.
Scikit-learn は上記のような使い方ができるため,どのような分類器がどのような名前 で,どのようなパラメータを必要としているのかさえ分かれば, とても簡単に機械学習を行うことが可能です.
注釈
Scikit-learn で実装されている分類器について
Scikit-learn で実装されている分類器についての詳細は, 公式のドキュメントが非常によく整備されています. このページでもできる限り日本語化して説明をしていきたいと思っておりますが, なんだかんだで公式のドキュメントを追いかけていくのがてっとり早いかと思います.
Toy セット, サンプルデータに関して¶
Scikit-learn には, iris などのサンプルデータが収録されています. これによって, 少し,使い方を確かめたい機能を簡単に試してみることが可能です.
以下に, サンプルとして iris のデータを可視化するコードを記述しておきます.
- なお, Ipython を利用する場合, 起動時に ” –pylab ” をつける必要があります.
結果は以下のようになるはずです.
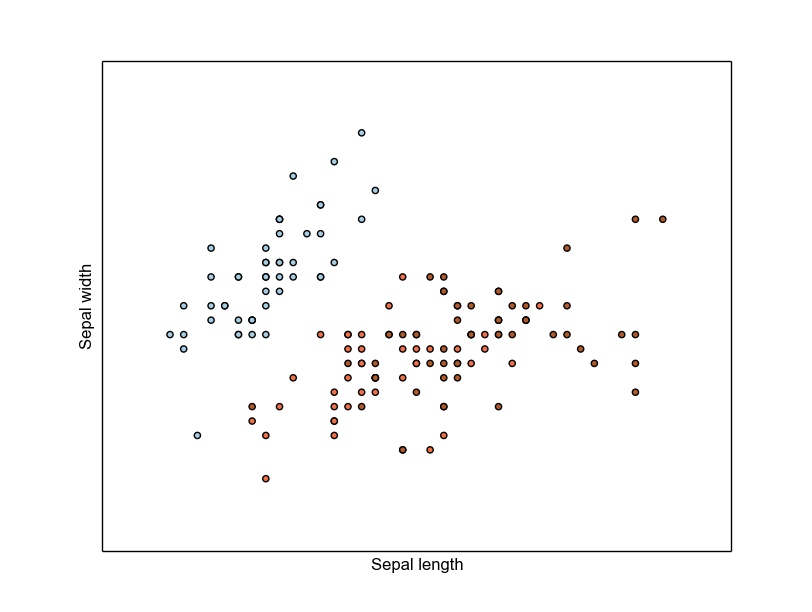
このサイトでは基本的に iris というデータセットを使用するつもりなのでこれに関して のみは簡単に紹介したいと思います.
サンプルデータのデータ構造について¶
iris のデータにはどのような情報が入っているのかを説明します. これを確認するには iris.keys() とするとわかりやすいです.:
>>> iris = datasets.load_iris() # サンプルデータ(iris)の読み込み
>>> iris.keys()
['target_names', 'data', 'target', 'DESCR', 'feature_names']
- target_names: 菖蒲の種類の名前
- target : それぞれの花がどの種類なのかのラベル
- feature_names : 各計測値の名前
- data : それぞれの花についての計測値
- DESCR : データについての引用その他
それぞれの値を確認するには以下のようにします.:
>>> iris.target_names
array(['setosa', 'versicolor', 'virginica'], dtype='|S10')
>>> iris.target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2])
単純に考えるなら target の 0 は target_names の 0 番目の要素かと思います.